Ashish PatelinCodebraceUsing Object Versioning for Google Cloud Storage!Usecase4 min read·Apr 8, 2021----
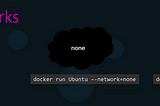
Ashish PatelinCodebraceUnderstanding Docker Networks and resolving conflict with Docker Subnet IP Range!As we all know, By default Docker creates 3 networks automatically Bridge, Host, and None network.3 min read·Mar 18, 2021----
Ashish PatelinCodebraceWorking on On-prem/External Airflow with Google Cloud Platform(GCP)If you want to work with Airflow and just starting up with your installation then Google Cloud Composer is the best solution, As it…4 min read·Mar 11, 2021----
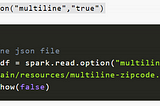
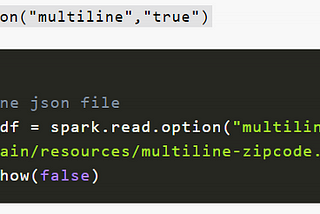
Ashish PatelinCodebraceWorking with JSON ( JSONL)& multiline JSON in Apache SparkFew days back I was trying to work with Multiline JSONs (aka. JSON ) on Spark 2.1 and I faced a very peculiar issue while working on…3 min read·Jan 10, 2021--3--3
Ashish PatelinCodebraceLeetCode Day #18 -Minimum Path SumProblem — https://leetcode.com/explore/challenge/card/30-day-leetcoding-challenge/530/week-3/3303/1 min read·Apr 20, 2020----
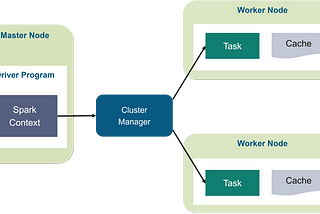
Ashish PatelinCodebraceHow Apache Spark runs our Application?In order to understand how your application runs on a cluster, an important thing to know about Dataset/Dataframe transformations is that…5 min read·Nov 26, 2019----
Ashish PatelinCodebraceVim Tutorial in 59 Minutes, Part — 1 Basicshttps://www.youtube.com/watch?v=kgP4FJ4uemM&t=573s2 min read·Jul 23, 2019----
Ashish PatelinCodebraceAdding Class Path for git-bashIf you have been using git-bash for command line operations and couldn’t able to find some class paths this blog might help you in adding…2 min read·Oct 26, 2018----